12 ways commercial SaaS can save your complex environmental data (part 2/4)
Continued from Part 1
 2) Data quality is better with databases
2) Data quality is better with databases
Since 2002, a dedicated group of Locus employees has been involved with migrating data into EIM from spreadsheets provided to us by customers and their consultants. As such, we have firsthand experience with the types of data quality issues that arise when using spreadsheets for entering and storing environmental data.
Here is just a small selection of these issues:
- Locations with multiple variations of the same ID/name (e.g., MW-1, MW-01, MW 1, MW1, etc.)
- Use of multiple codes for the same entity (e.g., SW and SURFW for surface water samples)
- Loss of significant figures for numeric data
- Special characters (such as commas) that may cause cells to break unintentionally over rows when moving data into another application
- Excel’s frustrating insistence (unless a cell format has been explicitly specified) to convert CAS numbers like “7440-09-7 (Potassium)” into dates (“9/7/7440”)
- Bogus dates like “November 31” in columns that have do not have date formats applied to them
- Loss of leading zeros associated with cost codes and projects numbers (e.g., “005241”) that have only numbers in them but must be stored as text fields
- The inability to enforce uniqueness, leading to duplicate entries
- Null values in key fields (because entries cannot be marked as required)
- Hidden rows and/or columns that can cause data to be shifted unintentionally or modified erroneously
- Bogus numerical values (e.g., “1..3”, “.1.2”) stored in text fields
- Inconsistent use of lab qualifiers— in some cases, these appear concatenated in the same Excel column (e.g., “10U, <5”) while in other cases they appear in separate columns
With some planning and discipline, you can avoid some of these problems in Excel. For example, you can create dropdown list boxes to limit the entries in a cell to certain values. However, this is not standard practice as most spreadsheets we receive come with few constraints built into them.
While databases are indeed not immune to data quality issues, it is much easier for database designers to impose effective constraints on users’ entries. Tasks such as limiting the values in a column to selected entries, ensuring that values are valid dates or numbers, forcing values to be entered in selected fields, and preventing duplicate records from being entered are all easy to implement and standard practice in databases.
However, properly designed databases can do even more. They can check that various combinations of values make sense—for example:
- They can prevent users from entering analysis dates that are earlier than the associated sample dates.
- They can verify that numerical entries are within a permitted range of values and make sense based on past entries. This is so popular its even part of our Locus Mobile app for collecting field data.
Databases also provide the ability to verify the completeness of your data:
- Have all samples been collected?
- Have all analyses been performed on a sample?
- Are there any analytes missing from the laboratory’s findings?
You can specify such queries to run at any time. Replicating these checks within Excel, while not impossible, is simply not something most Excel users have the time, skill, or desire to build.
 3) It’s easier to prevent data duplication and redundancy when your data resides in your database
3) It’s easier to prevent data duplication and redundancy when your data resides in your database
One of the most striking differences between spreadsheets and databases is the prevalence of redundant information in spreadsheets. Consider, for example, these three tables in EIM:
- LOCATION
- FIELD_SAMPLE
- FIELD_SAMPLE_RESULT
In this subset of their columns, “PK” signifies that the column is a member of the “primary key” of the table. The combination of values in these columns must be unique for any given record.
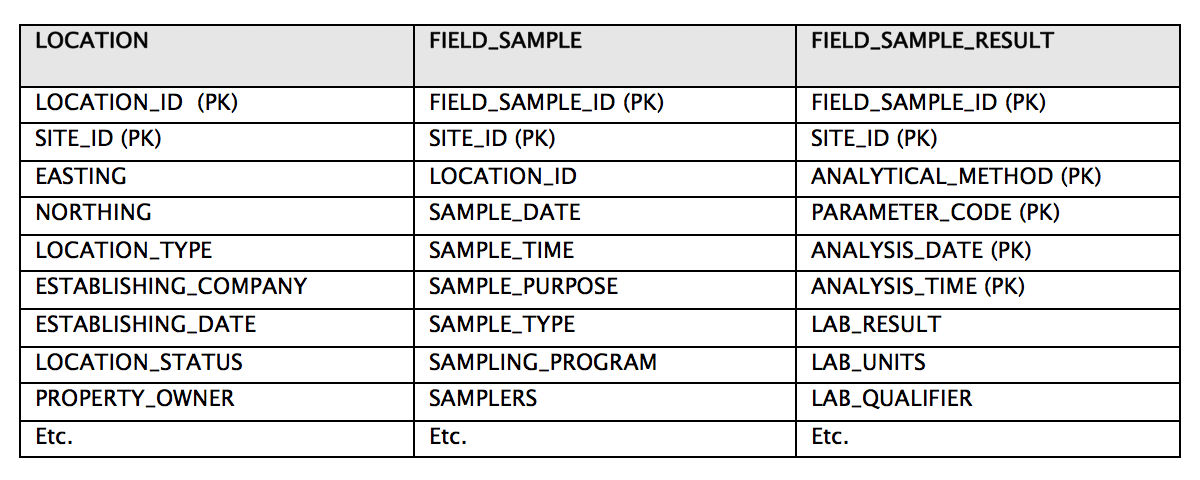
The two columns LOCATION_ID and SITE_ID can be used to link (join) the information in the FIELD_SAMPLE table. Furthermore, FIELD_SAMPLE_ID and SITE_ID can be used to link the information in FIELD_SAMPLE_RESULT to FIELD_SAMPLE. Because these links exist, we only need to store the above attributes of a given location or field sample once— in one table. This is very different from how data is handled in a single spreadsheet.
Let’s compare how the data in a few of these columns might appear in a single spreadsheet compared to a database. We’ll look at the spreadsheet first:

Next, let’s see how this information would be stored in a database. Here we can see more fields since we’re not as constrained by width.
First, the LOCATION table:

Then, FIELD_SAMPLE:

Lastly, FIELD_SAMPLE_RESULT:

Note one of the most striking differences between the spreadsheet and the database tables above is that much redundant information is included in the spreadsheet. The Location Type of “WELL” is repeated in every record where location MW-01 appears, and the sample date of “04/17/2017” is repeated wherever sample MW-01-12 is present. Redundant information represents one of the most significant drawbacks of using spreadsheets for storing large amounts of data when many of the data values themselves (e.g., LOCATION_ID and FIELD_SAMPLE_ID above) have multiple attributes that need to be stored as well.
Most spreadsheet data that we have received for import into EIM have consisted of either:
- Multiple worksheets of the same or similar formats, all containing a combination of sampling and analytical data
- A single worksheet containing tens of thousands of rows of such data
Occasionally, customers have sent us multiple spreadsheets containing very different types of data, with one or more hosting sample and analytical results, and others containing location, well construction, or other supporting data. However, this is atypical; in most of the migrations that we have performed, redundant data is pervasive in the spreadsheet’s contents and inconsistencies in entries are common.
Entering new records in a spreadsheet structured like the example above requires that the attributes entered for LOCATION_ID and FIELD_SAMPLE_ID be consistent across all records whose values are the same in these columns.
The real problems surface when you have to edit records. You must correctly identify all affected records and change them all identically and immediately.
Sounds relatively straightforward, doesn’t it?
In fact, judging by what we have seem in our data migrations, discrepancies invariably creep into spreadsheets when edits are attempted. These discrepancies must be resolved when moving the data into a database where constraints prohibit, for example, a single sample from having multiple sample dates, times, purposes, etc.
In addition, audit trails are all but nonexistent in Excel. Many users tend to save the edited version with a new filename as a crude form of audit tracking. This can quickly lead to a data management nightmare with no documented audit tracking. Just as important, almost all our customers, especially customers involved with regulatory reporting, require audit tracking. This is typically required on sites that may be involved in litigation and decisions are made on the health and safety risks of the site necessitating defensible and unimpeachable data.
 4) Entity relationships are more manageable in databases
4) Entity relationships are more manageable in databases
The discussion of data duplication and redundancy touches on another significant difference between databases and spreadsheets—how entity relationships are handled.
Excel stores data in a two-dimensional grid. While it is possible to create relationships between data in different worksheets, this is not the norm and there are many limitations. More often, as we have stated elsewhere, Excel users tend to store their data in a single spreadsheet that grows increasingly unwieldy and hard to read as records are added to it.
Let’s consider some of the relationships that characterize environmental sampling and analytical data:
- Sampling locations are associated with sites or facilities—or, for our water utility customers, individual water systems. They may also belong to one or more planned sampling routes.
- Different sampling locations have their own analytical and field measurement requirements.
- Individual samples may be associated with one or more specific permits or regulatory requirements.
- Trip, field, and equipment rinsate samples are linked to one or more regular field samples.
- Analytical results are assigned to analysis lots and sample delivery groups (SDGs) by the laboratory.
- Analysis lots and SDGs are the vehicle for linking laboratory QC samples to regular samples.
- Analytical parameters are associated with one or more regulatory limits.
- Individual wells are linked to specific boreholes and one or more aquifers.
Modeling and building these relationships in Excel would be quite difficult. Moreover, they would likely lack most of the checks that a DBMS offers, like preventing orphans (e.g., a location referenced in the FIELD_SAMPLE table that has no entry in the LOCATION table).
 5) Data reporting and integration is faster and easier with databases
5) Data reporting and integration is faster and easier with databases
How do you create a report in Excel? If you’re working with a single spreadsheet, you use the “Data Filter” and “Sort” options to identify the records of interest, then move the columns around to get them in the desired sequence. This might involve hiding some columns temporarily.
If you make a copy of your data, you can delete records and columns that you don’t want to show. If your data is stored in multiple spreadsheets, you can pull information from one sheet to another to create a report that integrates the different types of data housed in these spreadsheets. But this is a somewhat tedious process for all but the simplest of reports.
Let’s contrast this drudgery with the simplicity and power offered by relational databases.
In Locus EIM, for example, you pick the primary and secondary filter categories that you want to use to restrict your output to the records of interest. Then, you select the specific values for these data filter categories (usually from dropdowns or list-builder widgets). There is no limit on how many categories you can filter on.
Typically, you then choose a date range. Lastly, you pick which data columns you want to view, and in what order. These columns can come from many different tables in the database. For ease of selection, these also appear in dropdowns or list-builder widgets.
When you have made your filter selections, Locus EIM pulls up the records matching your selection criteria in a data grid. You can further filter the records by values in specific columns in this grid, or hide or rearrange columns. If you want to share or keep a record of these data, you can export the contents of the displayed grid to a text file, Excel, XML, PDF, or copy to your clipboard.
The list of reports spans all the major types of data stored in Locus EIM, including location and sample collection information, chain of custody and requested analyses data, analytical results, field measurements, and well and borehole data. Additional reports provide options to perform statistical calculations, trend analyses, and comparisons with regulatory and other limits.
In short, when it comes to generating reports, databases are superior to spreadsheets in almost every aspect. However, that doesn’t mean spreadsheets have no role to play. Many Locus EIM users charged with creating an ad hoc report prefer to download their selected output to Excel, where they apply final formatting and add a title and footer. Although, with some of the newer reporting tools, such as Locus EIM’s new enhanced formatted reports, that functionality is also built into the DBMS. The more sophisticated the database, the more advanced and robust reporting options will be available.

Make sure to read the entire series to find out about 12 reasons commercial SaaS databases excel at managing complex environmental data!
About the author—Gregory Buckle, PhD, Locus Technologies
 Dr. Buckle has more than 30 years of experience in the environmental field, most of which have been devoted to the design, development, and implementation of environmental database management systems. When he joined Locus in 1999, he was responsible for building and deploying Locus’ cloud-based EIM software. He was also instrumental in customizing EIM for the water utility industry and developing EIM’s powerful Sample Planning and Data Validation modules. The latest iteration of the Sample Planning module that Dr. Buckle built is currently being used by Los Alamos National Laboratory and San Jose Water Company to plan and schedule thousands of samples per year.
Dr. Buckle has more than 30 years of experience in the environmental field, most of which have been devoted to the design, development, and implementation of environmental database management systems. When he joined Locus in 1999, he was responsible for building and deploying Locus’ cloud-based EIM software. He was also instrumental in customizing EIM for the water utility industry and developing EIM’s powerful Sample Planning and Data Validation modules. The latest iteration of the Sample Planning module that Dr. Buckle built is currently being used by Los Alamos National Laboratory and San Jose Water Company to plan and schedule thousands of samples per year.
About the author—Marian Carr, Locus Technologies
 Ms. Carr is responsible for managing overall customer solution deployments and customer relationships with Locus’ government accounts. Her career at Locus includes heading the product development team of the award-winning cloud-based environmental ePortal solution as well as maintaining and growing key customer accounts with Locus’ Fortune 100 enterprise deployments. In addition, Ms. Carr was instrumental in driving the growth and adoption of the Locus EIM platform with key federal and water organizations.
Ms. Carr is responsible for managing overall customer solution deployments and customer relationships with Locus’ government accounts. Her career at Locus includes heading the product development team of the award-winning cloud-based environmental ePortal solution as well as maintaining and growing key customer accounts with Locus’ Fortune 100 enterprise deployments. In addition, Ms. Carr was instrumental in driving the growth and adoption of the Locus EIM platform with key federal and water organizations.

